")
Instaknow’s technology is protected by U.S. patents 6732102, 7073126, 7437342, 7979377, 9443005, 11568666, and additional pending patents.
Instaknow’s Insta-Intelligence® – Competitive Extraction Products Feature Comparison
(compared with offerings from other OCR and Data Extraction solutions)
No. | Feature | Instaknow | Competing Solution | Comments |
1 | Built-in, full-fledged, multi-system process orchestration using Humanvision AI to interact with browsers, screens, Excels containing data in unknown formats | Yes | No | No competing extraction technology provides process orchestration. Another product must be used and integrated for that. Instaknow has both data extraction and further processing orchestration as an integrated offering. |
2 | Instaknow does NOT use machine learning. No document examples are needed. Simply define visual rules, similar to the instructions given to a person. | Yes | No | A few competing technologies can follow basic visual rules & instructions (right/left/above/below label). Instaknow (with its unique ability to find “Related” content) can automatically find data related to the label without needing to specify if it is right/left/above/below the label. |
3 | Detect and separate sub-documents that happen to be together inside a single PDF, regardless of subdocument order. | Yes | No | A physical file may intentionally or unintentionally combine multiple sub-documents. Instaknow detects the beginning and end of each sub-document of interest and process it regardless of its order inside the file |
4 | Auto-detect all typical labels on all pages, without needing to specify them | Yes | No | Example
from a legal document:
|
5 | Detect and ignore page headers and footers – needed to extract details from paragraphs that wrap from the bottom of one page to the top of the next page | Yes | No | Example
of a page footer that must be ignored from a legal
document to read a list of items:
|
6 | Detect and extract multiple items of interest in middle of paragraphs even when they have unknown occurrences and locations/p> | Yes | No | Example from legal documents showing amounts in a paragraph:  |
7 | Detect and use labels wrapped in the middle of a page, e.g. section descriptors or column headers of a table and look only below that narrow vertical band | Yes | No | Other extraction engines need label words to be in a single line. This limits their practical usage in complex documents. e.g. Holiday Schedule from legal document:  |
8 | Automatically detect and extract entire tables, even when they have unknown number of rows and columns | Yes | No | Examples from court Judgements showing unknown number of rows: 
 |
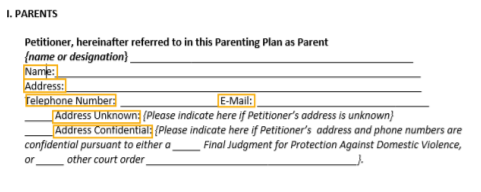
9 | Very accurately detect checked/unchecked checkboxes and radio buttons | Yes | Unknown |
 |
10 | Redact or highlight required data even when it is at unknown locations | Yes | No |
 |
11 | Built-in Natural Language Processing (NLP) provides semantic (“meaning”) based detection of relevant data | Yes | No | Allows far more flexible detection of data of interest than competing data extraction products |
12 | Ability of comparing complex clauses with a “standard text” and flagging semantic discrepancies | Yes | No | e.g. detect that the expected clauses are missing from a document |
TOTAL SCORE OF 'YES' | 12 | 0 |